
此文是俺在知乎上对这个问题的回复:
知乎链接:入职后发现项目组代码异常混乱,是去是留?
楼上的@蔡磊兄分析得很清楚。对重写代码可能带来的各种风险,俺很认同他的观点,也就不再多嘴了。然而,蔡磊兄整体的论调呈相对消极的姿态,从不同角度得出这一个结论——重写代码是不可取的。这里俺更愿意换个角度,谈谈积极的一面,也发出一点不同的声音。
再谈重写
在展开讨论之前,先抛出结论:对于商业价值已在明显缩水中的项目,大动干戈意义确实不大;而对于一个急速成长或稳定运行中的项目而言,有计划有步骤地整理和翻新,是非常必要而且很有讲究的。各种在初期不会显山露水的局限和瓶颈,会随着项目规模的成长不断凸显,此时,若不能水涨船高,通过积极手段逐步改良其内部实现,随着贪一时之快的补丁越积越多,系统将日趋僵化,后果自不必说。
对于重写本身,我们也大可不必畏之如虎。虽说正如 Joel 所说,“废弃现存可运作的代码跑去完全重写”几乎总是个错误的决定,但“中小型系统或组件的受控重写”却是很常见的改良系统的手段。比如这个:
Rewriting a large production system in Go
在这篇文章里,Matt Welsh 同学介绍了自己是__如何使用 Go 来完全重写一个 Google 的生产环境下的系统__的。推荐感兴趣的同学前往一读。此外我读过一篇讲 facebook 是如何决定和实施一个服务的重写的,还有一篇是 GitHub 如何保证重写的新系统和老系统之间无缝平滑过渡的,这两篇都蛮有趣,可现在一时之间找不到链接了,不过没关系,后面我会介绍一些我仍记得的思路。至于微软是如何(反复)重写 Windows 组件的大家可以到 The Old New Thing 上去看,老的例子有 GDI, Direct3D, Visual C++, MSE,新的例子则有 Edge (IE)。
关于从 IE 到 Edge 还有一个有趣的曲折——其实自从 IE8 之后微软就动了重写的心思了,在 IE9 中,微软尝试了所谓的“完全重写 (Rewrote From Scratch)”(可以参考这个链接:Inside IE9: How Microsoft rewrote its browser from scratch) 这个版本里把原来的 Javascript 解释器替换为一个新写的能生成本地的 native code 的执行引擎,把图形系统内的大多数渲染工作挪到了 GPU 上,还有一个全新的布局引擎 (With IE9, we rewrote our layout engine from scratch) 但是(这里才是重点),就连这种程度的重写也还是不够的,微软后来才意识到,人们的关注点变了,互联网的焦点已经在向移动端转移,于是才有了现在更彻底的重写——Windows Edge(原来的 code name 叫 Project Spartan)
好了,在了解到在有重大商业影响的项目中,重写也不是什么偶然的事情之后,我们就会明白,已有的 Legacy Code 并非刻在石头上的神谕,尝试着去逐步改进自己维护的代码,重点不在于“能不能”,而在于“应不应该这么做” ,“如果需要,应该做到什么程度?”,还有“实践中,如何以受控的方式去实施”,这样才能在避免失控的悲剧的同时,周期性地抛下越来越沉重的负担,让系统得以轻快而长久地健康运行。
Legacy Code 在不同的人眼里长什么样?
在新来的萌宠小师妹眼中,现有系统是这样的:
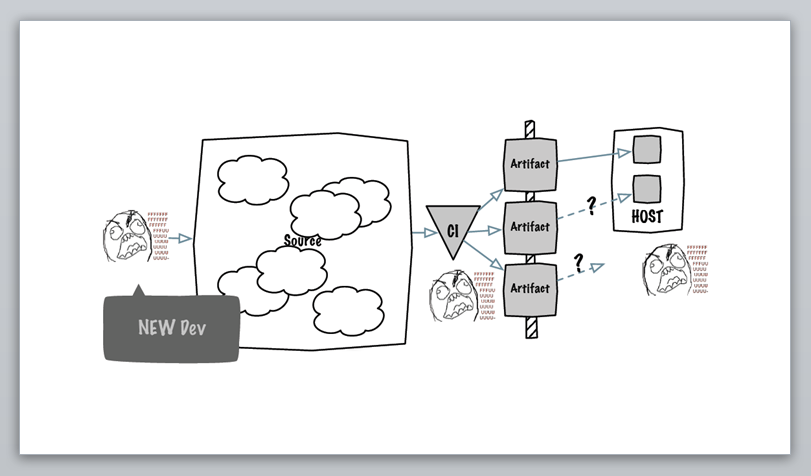
在曾经沧海的大师兄眼中,现有系统是这样的:

在新加入的同事眼中,大概还能分得出的几坨貌似解耦的模块,(由于各种不足为外人道的潜规则)在老同事眼里,其实跟一整坨也没什么区别。不同的是,老同事对系统的全貌和脉络,至少还有逻辑上的概念,知道整个系统的重心和支撑点在哪儿,知道那茂密毛发下面隐藏着什么(……)。
所以,在你感觉眼前的代码比较混乱的时候,想想这头牛吧。虽说不管毛长毛短,能挤奶的就是好牛,可为了让自己以后能活得轻松点,给它洗洗澡剪剪毛啥的还是值得考虑的。
标准的受控重写 (Managed Rewrite) 应该长什么样?
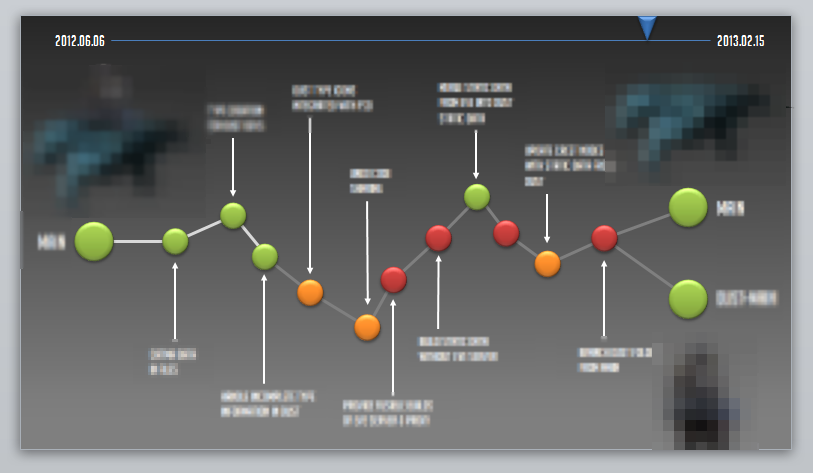
当你决定撸起袖子大干一场的时候,如果没有上图这样的详细计划和分步的路线图,而只是盲人摸羊,走到哪里算哪里的话,会很容易掉到坑里的,达到预期的可能性也会大大降低。请注意,这张图最重要的价值在于,它把一个风险很大的单步决策__拍碎成了许多细碎的小步骤__,每个步骤彼此独立,需要承担的风险或重要性用颜色表示。这样一方面清晰地知道自己的目标和进展,不会迷失方向;另一方面也随时保留可以撤销至某个安全点上的能力。
进化 (Evolution),而非革命 (Revolution)

这与上一张图表达的实际上是一个意思。正如在做代码重构时的策略那样,我们在战略上也把大的目标切成小块,始终谨慎地保持小步前进,始终避免做过大的决定,始终把风险控制在能接受的范围内。
平行实现 (Parallel Implementations)
__平行实现__是完全重写某个服务的重要手段,关于这个主题 John Carmack 曾写过一篇非常精彩的文章 “Parallel Implementations”,现在由于 altdevblogaday 这个网站关闭链接已经失效了,不过大家可以在 Internet Archive 这个网站上找回此文章在 2012 年时的快照。此文非常精彩,强烈推荐。
此文是这样开头的:I used to Code Fearlessly all the time, tearing up everything(!!!) whenever I had a thought about a better way of doing something. There was even a bit of pride there — “I’m not afraid to suffer consequences in the quest to Do The Right Thing!” 三个黑色加亮部分体现了卡马克同学一贯的价值观,俺写到这里心里默默为卡神点了三个赞。
整个文章的精华在这一段:
What I try to do nowadays is to implement new ideas in parallel with the old ones, rather than mutating the existing code. This allows easy and honest comparison between them, and makes it trivial to go back to the old reliable path when the spiffy new one starts showing flaws. The difference between changing a console variable to get a different behavior versus running an old exe, let alone reverting code changes and rebuilding, is significant.
还有这一段:
There are two general classes of parallel implementations I work with: The reference implementation, which is much smaller and simpler, but will be maintained continuously, and the experimental implementation, where you expect one version to “win” and consign the other implementation to source control in a couple weeks after you have some confidence that it is both fully functional and a real improvement.
文章的最后,卡神写到:
Every single time I have undertaken a parallel implementation approach, I have come away feeling that it was beneficial, and I now tend to code in a style that favors it. Highly recommended.
正是因为这几段都很精彩,所以原封不动摘录于此。(其实要不是篇幅所限,真想干脆全文摘录了) 平行实现的细节我就不展开讲了,大家直接看原文好了。
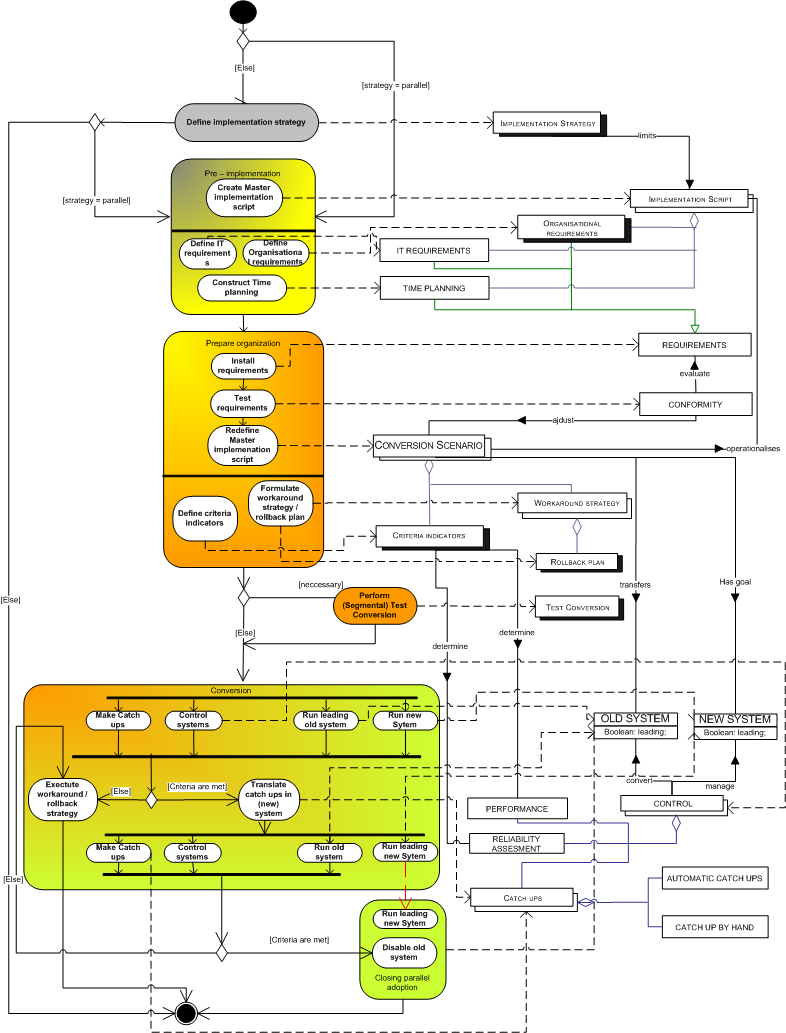
幽灵替补 (Ghost Alternative) ,柔性服务和灰度发布
“幽灵替补”是我为前文提到的一种做法随便起了个名字,方便记忆。前文提到,在一篇讲 GitHub 的某服务的重写过程中,他们把该服务的__新实现__挂在__老实现__上一起跑(正如附身的幽灵),当有新的请求过来时,新老两套系统同时开始处理,但最后的输出仍采用老系统的结果,新的系统输出结果被记录下来,与老系统的结果比对。千万次运行下来后,新系统得到了足够的考验,错误率低到一个程度后,再淘汰掉老系统。
写完了才发现这里(Parallel Adoption)有 wikipedia 上对此方法的综述,也可供参考。
这里是一个典型的例子:
至于最近说的比较多的柔性服务和灰度发布,可以参考这两篇:
这些技术,都可以帮助我们实现新老系统之间顺利的迁移和过渡工作。
总得来说,对系统的维护者来说,一味地积极重构,和一味的消极补丁,都是不可取的。有经验的开发者,会更准确地评估权衡改动带来的风险和工作量。如同我在“一个有趣的交互 bug ——兼谈游戏的引导系统”一文中提到的那样,大部分问题都可以由浅至深地分析出多个不同的解决方案,以便于在不同的情形下去取舍和平衡。
最后这句话,与大家共勉吧 :)

(全文完)