
本篇是我在 2021-04-15 BSV Bootcamp 上,关于 感应合约的简介和基本原理 的相关分享的文稿版。
演讲幻灯片 PDF 可以在此下载: 2021.04-bootcamp-sensible-contract-intro.pdf
2021.05 感应合约的简介和基本原理
背景
在今年 4 月,比特币协会在东澳岛主办了长达一周的 BSV 第一届训练营 (Bootcamp)。这次训练营上的第四天是 Sensible Day,全天都是感应合约相关的内容。
当日所有分享的幻灯片可以在感应合约的官网上的这个页面获取。
本篇是当天的第一讲,是关于 感应合约的简介和基本原理 的相关分享的文稿版。

大家好,我是顾露,是比元科技的创始人,也是小聪游戏的开发者,也是 Sensible Contract,也就是感应合约的参与者。今天早上的第一场演讲,我会给大家讲一下感应合约的简介和它的基本原理。

(你可以看到)有一个副标题是 “fix the past and build the future in a sensible way”,这实际上就是我们感应合约最核心的两点。也就是说,如果你今天只一页只打算看一页的话,那看一下这一页就可以了,因此我们叫它 Sensible Contract in a nutshell。
感应合约有两个基本出发点,一个是溯源,一个是协作。
- 溯源 能够帮助你从当前的交易往回看,用以确认以前曾经发生的交易跟自己是不是有关系。这个功能是感应合约一开始的出发点,所以我们叫它 Fix the past。
- 协作 是帮助不同的交易之间建立关系,准确的说,同一笔交易上的不同的输入,是否能够准确地识别对方并做出响应。通过协作,我们得以在未来构造更复杂的项目,所以叫它 Build the future。
昨天蒋杰也谈到,协作有多层的含义,既可以是多笔交易,多个比特币脚本之间的合作,也可以是同一个合约内部,不同的代码段之间的协作。由于单个合约,也就是单个解锁脚本,能做的事情非常有限,想要达到 “通过 (容易被定义的) 多个交易步骤来实现的契约自动化” 的效果(也就是我们周一时说的 “automation of agreements with easily definable transaction step”),就需要在多层次上的协作,才能完成比较复杂的工作。
正文

好,那么今天的内容我分成了三块:
- 第一部分是,开始深入感应合约前,你需要了解的一些预备的知识。
- 第二部分里,我会把整个过程拆分成单个独立的小步骤。为什么要分步?分步的好处就是,万一中间哪步没弄明白,你可以跳过它,直接看下一步,前后步骤之间没有那么强的相关性。
- 最后一个部分,我们上线以来,有不少同学在微信群里,或者私下里找我了解情况。问的不少问题是相似的,我把常见的问题整理了一下放在这里。这样的话,对于一些基本问题,我们的看法可以更明确一些。
准备知识
现在我们先看准备知识。

首先,是比特币脚本的简短历史中,几个比较重要的时间节点。
一开始,比特币脚本允许我们用可编程的方式来对比特币进行操作。
后来,sCrypt 工具出现了之后,开发效率提高了,我们得以使用一种高级语言的方式来实现比特币编程。
在去年,scrypt 为我们提供了一个机制,最开始是由 nChain 发现的 OP_PUSH_TX 技术,scrypt 把它做到了内置的功能里面,让我们能够有机会去读取交易里边的一些比较重要的字段信息,这些信息能帮我们做很多原来做不到的事。我们认为 OP_PUSH_TX 是很多技术得以实现的基础。
再后来,在 OP_PUSH_TX 的基础上又往前走了一步,有了 Stateful Contract,有状态的合约,使得我们能够把一个合约里的状态往后传递。去年老刘在分享时也讲过,这使我们得以实现一种状态机,使得比特币脚本能够不仅仅被用来控制单个交易了,可以通过多个交易来回跳跃了,在跳跃时还能携带自己的状态了,这个是我们后续可以做很多事情的基础。
好,这是比特币脚本发展历史上,几个比较重要的节点。一路走来,你可以看到我们能够运用的能力是不断提升的。然而另一方面,也存在一些始终未能被打破的限制。
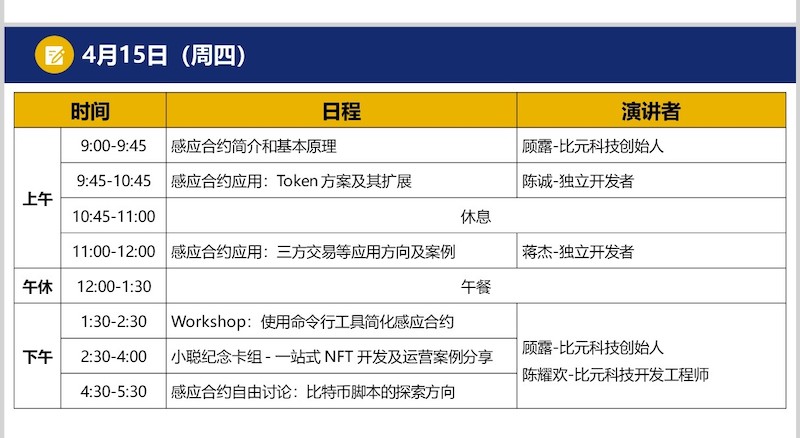
在我们的白皮书感应合约的白皮书里,你可以看到一张图,整个白皮书应该就只有这一张图。这张图主要是用来说明,在感应合约之前,比特币脚本能做什么,不能做什么。
你可以看到,图上就是打问号的那两个地方,正好对应着我们一开始提到的溯源和协作:一个是脚本往前追溯的能力,也就是 “我从哪里来”;另一个是脚本与它相邻的脚本,也就是跟同一笔交易内的其他输入之间的协作的能力,也就是 “我是谁/有谁同我一起?”。
这两个能力,我们认为是比较关键的能力。
好,我们首先来看前一个问题——溯源。

很自然地,你可能会问一个问题,我们为什么需要溯源?
因为需要解决 合法性 的问题。不仅仅是 token,很多比特币系统内的业务逻辑,都依赖于合法性问题的解决。
那么,究竟什么是合法性问题?
不管是 Token 也好,程序代码创造出的其他各类资源也好,在发行和转移的任意环节,都有可能被伪造。攻击者伪造之后,你的系统如果识别不出来真伪,或者说不能以最低的成本识别出来,就会造成灾难性的后果,或者说,至少也被迫需要处理许多你本来预期不到的情况,你的系统会异常的复杂。如果能够低成本实现这种防伪的工作,并将其收敛到非常小的区域,甚至是把它以用户无感的方式,以应用无感的方式把它给封装起来,那么不同的应用就可以更简单地使用自己创造的资源。

那么往前再走一步,脚本资源的合法性,为什么是一个需要被解决的问题?或者说,比特币的这个 satoshi 怎么就不需要溯源,不需要解决合法性问题呢?
这是因为,比特币本身,跟我们创造出来的资源是不一样的,比特币价值单位是 sat。大家知道, sat 是一个非常特殊的单位,是系统内部独立存在的,跟脚本没有直接关系。你的每一聪,都是一个独占的系统资源,独占性由节点软件来保证,这是系统的义务。
也就是说,比特币节点软件,有义务保证每一聪都会被正常的计算。
这种排他性和独占性,还表现在其他的地方:只要你能解锁,就能控制 utxo;你花了,人家就花不了,这是一种由系统赋予的独占性。不管你写的代码有多厉害,或者是写得很糟糕,无论如何,你都没办法去通过编程来增加它,或是减少它。它的数量恒定,脚本无关,也都是我们熟知的,非常重要的比特币特性。

那么 token 或者说其他的通过脚本创造的资源,跟比特币本身的价值单位有什么不一样呢?
我们通过比特币脚本创造出来的资源,其实是不具有这种 数量的恒定性 和 代码的无关性 的。假设你在脚本里算错了,不小心在某个很关键的业务节点上,多算了一步,或者说多加了一次,多减了一次,那么你的 token 可能就出问题了。或者说,你有某一个特殊的情况没考虑到,那么一旦发生,你的 token 可能就不能用了,或者这个 utxo 你没法解锁了。除了这种主观上的犯错,当其他人发现了系统缺陷之后,成功地伪造了一笔能够通过你的检测的 token,这也是有可能随时会发生的情况。
不管主观原因也好,客观原因也好,都是因为 token 不是比特币系统的 “一类公民”,所以我们才需要通过某种机制去确保它的合法性。
为什么一开始我把这个问题说得这么细,因为这就是我们整个解决方案的出发点。我们一定要知道比特币脚本它本身的限制,也就是最开始的边界在哪里,才可以知道这个东西的适用性,能帮我们提升哪方面的能力。

好,我简单介绍一下,在 Sensible 之前的 BTP,也就是一种典型的依赖 oracle 的方案,是怎么来解决这个问题的。在感应合约前,也出现了很多系统,有很多 token的方案,国内和国外都有。
BTP 的方案是基于一个外部 oracle 的,它通过 oracle 来实现了一个区块链外部的机制来维护 token 的合法性,可以看作是区块链的插件。
从实现的角度,它维护了一个 utxo 集,来保证能以最低的成本确认 utxo 是否合法。这个解决方案非常精巧。
然而,从工程角度,如果因为创建和维持了一个 off-chain 状态,这个状态是存在于区块链之外的,那么就得持续维护,确保它始终是可用的。这就涉及到状态要及时更新,当出现问题的时候,它需要能被随时恢复。在真实环境中可能会出很多预期之外的问题,不仅仅是软硬件的问题,还有其他的各种问题,比如节点限制,节点状态,内存池状态等等,会导致服务不可用。除此之外,这个链外状态集还需要关心状态的膨胀,因为比特币的 utxo 是不断增大的。然后也需要考虑部署多个 oracle 来避免单点。
总得来说,一旦引入了一个状态的话,你就要对它负责,做更多的事情。
好,这是在 Sensible Contract 之前,一个典型的 oracle 的方案,是怎么解决合法性问题的。

开始之前,我再简单介绍一下 OP_PUSH_TX。理解了 OP_PUSH_TX,有助于你了解 PreImage 的作用。
我们可以看到,右边的这 10 个字段,对应 PreImage 结构,这个结构在解锁的时候你把它传进去,就可以通过一个生成的私钥,使用 OP_CHECKSIG 来证明它是真实有效的字段。这就是 OP_PUSH_TX,通过它,我们得以把交易的关键信息推入堆栈,使得你的比特币脚本逻辑能够验证并利用这些信息。
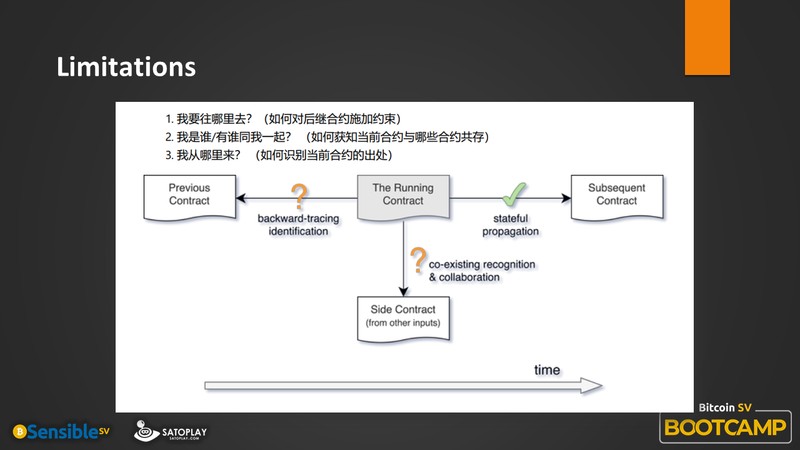
紧接着,我再介绍一下 Stateful Contract。
大家看一下图,PreImage 第 8 个字段字段是 hash output,能够把当前你正在操作的交易的所有输出哈希一下,这就能被用来验证并保证后继交易的输出脚本一定是你想要的样子。通过这个机制,它可以实现从前一笔交易到后一笔交易的逻辑上的延续性。

好,到这里我们小结一下。
在准备知识里,我们看到了比特币的演化,看到了合约的限制,看到了为什么脚本从本质上需要溯源来保证合法性,然后一个典型的 oracle 方案是怎么来解决溯源的,我们也简单地了解了 OP_PUSH_TX 和有状态的合约的实现。

接下来,我们开始进入 Sensible Contract 相关的内容。
分步讲解

在开始之前,我们先有几个约定,不然的话,很难通过讲述把话说明白,很容易绕进去出不来。
我们定义了三个概念,这个有点绕,我慢慢说,大家看一下。第一个概念是,你当前正在解锁的 utxo 所在的交易,也就是大家可以看到右下角的 “当前交易”。 我为什么要解锁一个 utxo,因为我要进行某个操作。
现在注意,我需要解锁的 utxo 一定是来源于一笔有效的交易,不然我没法拿着它。这笔有效的交易,我们叫它 PreTX,也就是 “前序交易”。为什么叫 PreTX?因为它是当前交易的前一笔交易,所以叫 PreTX。
我们给它另外定个名叫 TXn,意思就是第 n 笔交易。
那 PreTX 的前一笔是什么呢?我们叫它 PrePreTX,很自然的,可以被称为 TXn-1。
这样就比较清楚了,你知道现在我们有了 TXn,也有了 TXn-1。
最后一个概念是,所有这些交易追溯到最初的第一笔源头的交易。就像初始区块一样,这个交易我们叫它 创世交易,也就是 GenesisTX,我们也给它一个名字叫 TX0。
图上你还可以看到,在这一串交易中间,有一条竖线,这条竖线表示当前你所在的位置,也就是 “想要解锁还没解还没成功解锁” 这个状态。
接下来的讲述,就会围绕 PreTX,PrePreTX 和 GenesisTX 这几个交易之间的关系展开。

首先我们先来看一看,一个简单的回溯方案是怎么做的。很简单,一页PPT就可以讲完。
他是怎么做的呢?我们知道有状态合约能往后延续,但是不能往前回溯。怎么往前回溯?很简单,你把前一笔交易 PreTX 跟前前一笔交易 PrePreTX 都传进去,然后确认他们俩直接相关,这种相关性是真实有效的,那么不就能证明 TXn 和 TXn-1 是直接相关的了吗?
这是一个我们能想到的最直接的方案。
这个方案听起来理论上无懈可击,只有一个问题:会导致膨胀。

你可能会问,为什么会膨胀?
因为我们把前面的交易推到后面交易里,然后把后面的交易再推到更后面的交易里,前面的交易不断堆积到后面的交易里,就会导致单个交易整体上不断膨胀。
那膨胀得有多快?
答案是,非常快。准确说,这是一个斐波那契膨胀,因为 TXn+1 的尺寸,是 TXn 和TXn-1 的尺寸之和,除此之外,还包含了一些它自己的信息,所以实际上是略略超过正常的斐波那契数列的。它的增长速度接近 2n,看看下面这个图,就知道膨胀的速度是非常快的。
这里我们之所以关注膨胀问题,是因为它就是 Sensible Contract 在一开始的出发点。从这里出发,我们可以一步一步勾勒出全貌。我尽量按照故事本身的来龙去脉来讲述,这样逻辑整体上自然,容易理解一点。

好,现在我们要想解决膨胀的问题,那么怎么有效地消除这种膨胀呢?
我们分析一下膨胀的来源。膨胀的内容是在解锁脚本里的,对吧?正是因为你需要解锁,才需要把 PreTX 和 PrePreTX 给推进去,那么所有导致膨胀的东西,都在解锁脚本里。那么很自然的,我们就会想到,解锁脚本是那个具有“膨胀性”的东西,你不能一股脑把所有东西都塞到解锁脚本里,应该只放那些 有限且固定 的东西。

到这里就已经比较明确了,什么是 有限且固定 的东西?
对,就是锁定脚本。
使用锁定脚本有两个原因。
- 锁定脚本可以拿来识别脚本的行为,因为脚本就是行为,如果锁定脚本一样,那么行为就一样。
- 锁定脚本虽然可能是很长的一堆代码,但它是固定长度的,不会没有限制地增长。
所以很自然的,我们想到,是不是可以把锁定脚本直接推进去,这样不就能保证行为一致性又不膨胀了,对吧。

然而,问题又来了,如果说锁定脚本可以作为指纹,被用来做匹配,这样就足以维护一个有效的 token 系统了吗?

其实是不够的。
因为,从攻击者的角度,完全可以给你弄一个一模一样的锁定脚本,而且这个锁定脚本跟你系统毫无关系,是一个来自外部的交易,然后也能通过检测。
这时候怎么办?
此时很自然的,我们就会去想,应该通过某种机制,不仅保证它的内容是一样的,而且能够确保交易前后的相关性。
那么如何确保相关性呢?
可以通过签名的方式来实现。
这里我们用的是 Rabin 签名,昨天蒋杰也讲过。Rabin 签名的特点是什么呢?验签非常简单,很方便在脚本里通过简化的计算就可以验证这个签名。
具体地说,这个 Rabin 签名,用的时候分成两步:
- 首先,使用合约之前,我们在合约外对我们需要的那几个字段做签名;
- 然后,在合约内部去验证这个签名,来确保我们签的那几个字段是有效的。
通过这两个步骤,我们就可以确认他们的相关性了。
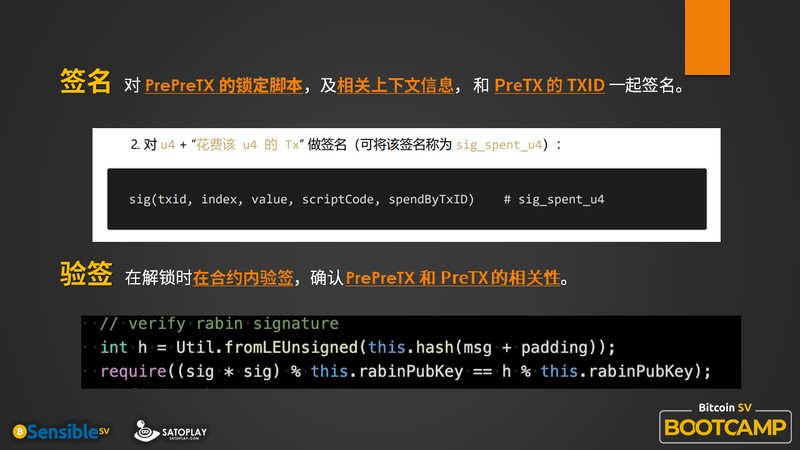
这个时候,你关心的是,究竟需要哪些信息,才能帮助你确认前后交易,也就是 PreTX 和 PrePreTX 的相关性。所谓相关性,就是说,如果我们有两笔交易,a 和 b,可以明确地确认 a 是 b 的直接后继,这就是相关性。
那么哪些字段能够被用来做这个事呢?
你可以看到感应合约的白皮书里面提到这样一个叫 u4 的东西,也就是图上这个结构。
对一个(解锁中的)合约而言,u4 内包含了我们认为是最有价值的几个上下文的信息。当然,如果想扩展它做更多的事情,也可以放入其他的信息。但是就目前而言,最必要的就是这几个信息,一个是它的 outpoint(也就是 txid 和 index),然后是锁定脚本,它的比特币数量(也就是 satoshi amount),最后,也是最关键的东西,就是这一笔交易是被谁花费的(也就是 spent_by_txid 字段).这个字段是最关键的,因为正是由他来确定,前面给出来的 outpoint,是被后面的这一笔 txid 花费了。
系统通过 Rabin 签名的方式把这两笔交易绑定到一起,这样你在合约里就可以去验证(对应着 PPT 上位于屏幕下方的验签逻辑)——前面的输出确实是被后面的 txid 给花掉了,于是就可以确认 PreTX 和 PrePreTX 它们俩的相关性了。
这个签名出现在这可能有点突兀,大家看白皮书的时候可能会有点懵,怎么突然就冒出来一个签名呢?实际上,这个签名的目的很单纯,就是为了解决相关性的问题。就是为了向你证明,不仅仅锁定脚本是一致的,而且它也确实来自于 PreTX 的前一笔交易,也就是 PrePreTX。
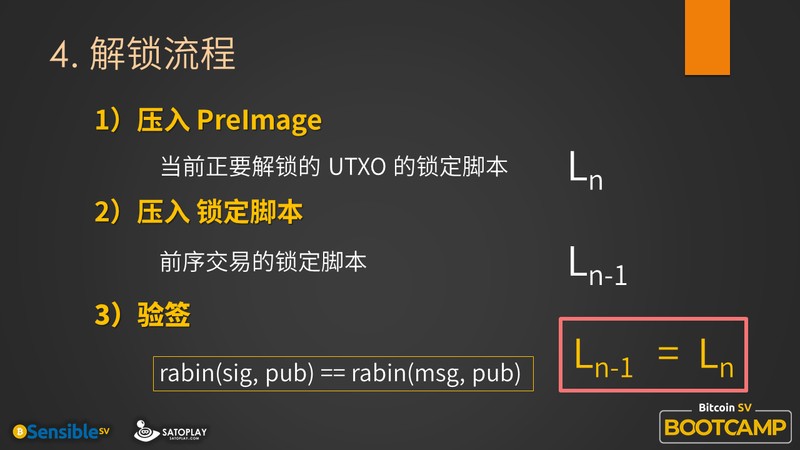
好,现在回顾一下刚才我说的流程,首先你在解锁时把 PreImage 压进去,这样你就得到当前正要解锁的 utxo 的锁定脚本,我们叫它 Ln (L就是 Locking script 的意思);然后,把你需要的锁定脚本压进去,就是前序交易的锁定脚本,我们叫它 Ln-1,那么你实际上你已经知道了 TXn-1 与 Ln 一致,但你并不知道它的合法性是怎么保证的,也就是接下来的第三步。
在第三步里,我们需要去验证它,通过验证这个 Rabin 签名,我们得以确认 Ln-1 = Ln 的合法性是可被验证的,所以套上个红框,表示它们俩确实是有这个相关性。

好,这里请大家注意一下,我们一开始的初始方案,保证锁定脚本完全一致,其实是一个最简单的方案。实际上还有很多方案,只要你能够保证他们之间的授权关系,并不一定是非得要压入一个完整的锁定脚本,并且保证他们完全一致,其实有多种方案,锁定脚本一致只是我们最开始的方案。
今天接下来的课程里,陈诚与蒋杰会与大家分享,我们在不同的情况下,怎么样用一些扩展的方案来解决问题。
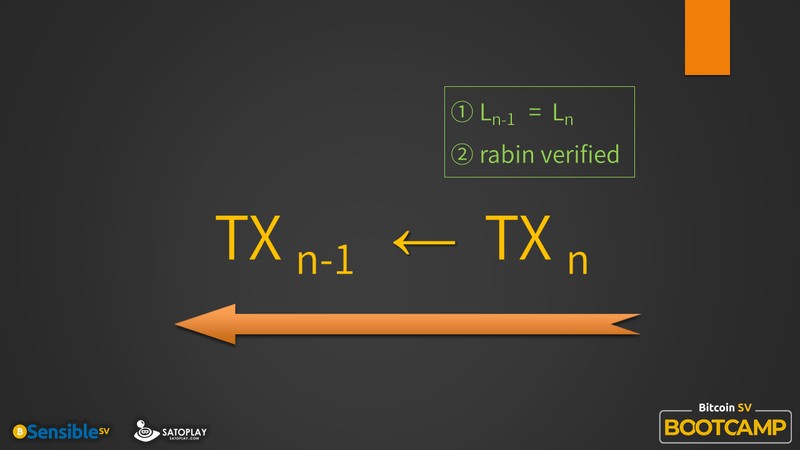
好,确定了单个交易的相关性之后,我们通过图的方式,可以把“从单个交易到整个交易链条”的推导过程,说得更清晰更明确一些。系统的有效性得以从单一扩展到整体。这个过程有点抽象,用图来表示会比较容易理解。
正如你看到的那样,在当前的这笔交易和过去的那笔交易之间建立关联性,需要两个条件,第一个条件是锁定脚本一致,第二个条件是签名被验证。这样我们可以从当前交易回溯到上一笔交易。
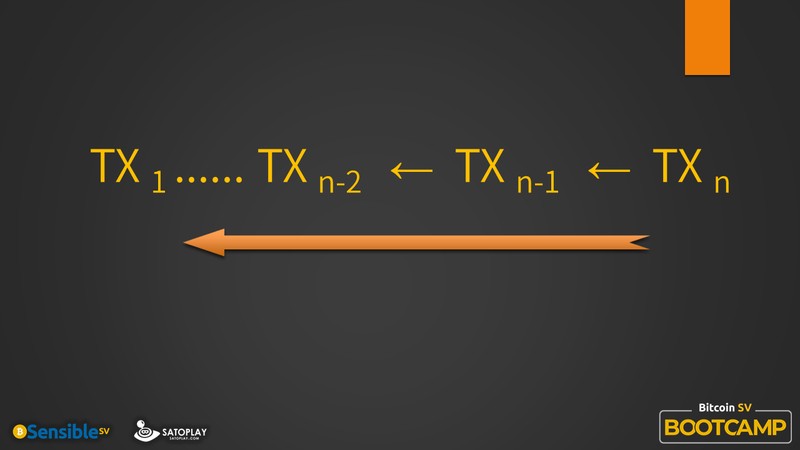
这个时候,我们理论上是可以这样一路回溯上去的。当然其实你是不用做这件事,为什么?因为区块链已经固化到区块里了,你实际上不用手动做这件事。但是从逻辑上讲,它是这样一步一步推过去的,从当前交易你可以建立跟上一笔的相关性,而上一笔对应着上上笔…这样一路推过去,最终你会推到 TX1,也就是第 1 笔交易。
请注意,这个时候问题就来了:第 1 笔交易跟第 0 笔交易是怎么保证的?

第 1 笔交易跟第 0 笔交易,是通过创世交易的标记来保证的。
我们在创造 token 的时候,你不是要发一笔创世交易,表示我现在要创造 token系统吗?
你发的这笔交易 GenesisTX ,实际上是整个 token 系统的原点,那么它一定有一个独一无二的标识,我们把标识提取出来放到 token 系统里边,甚至从浏览器的角度,你只要看到这个标识,你就知道这个 token 一定是从那里来了。这个标识里可以写一些你需要的信息,来标识它的身份,让人一眼就能看出来它。这就好像百家姓一样,给定任何一个人,只要你知道他姓什么,立刻就知道了他是源自哪一个谱系。
我们通过匹配标识,来保证从第 1 笔交易到第 0 笔交易的相关性。

那么更进一步,怎么把这整个系统给连接起来呢?
在任何一笔合约里,你就会写这样的逻辑:对于任何一笔给定的合约交易 TXn 也就是你当前要处理的这笔交易,它要么来自于 TX0,那就是我刚说的第二种情况,它的上一笔是创世交易,它自己是 TX1。要么往前追溯,来自于 TXn-1,也就是说它的上一笔是一笔合法有效的交易。
只要你满足了(这两个条件中的任何一个),要么你自己是 TX0 后面的 TX1,要么你是TXn-1 后面的 TXn,只要你满足了这两个条件,就可以把中间的链条全部串起来。
这就是大家高中数学学过数学归纳法,对吧?他们的合法性是这样一步一步推出来的,数学归纳法就是这样工作的。

通过前面的推导,我们建立了合法性的推导过程:
任何一笔有效的交易 TXn,它的合法性,要么是来自于前一笔有效的合约交易 PreTX,也就是 TXn-1,要么是来自于创世交易 GenesisTX,也就是 TX0。同理,当你想创造新的交易时,合法性也会向后顺延,传导给它。

解释完合法性的传递,整个溯源逻辑就完整了。接下来说一下具体的实践。我们在实践中遇到了一个合约尺寸的问题,昨天蒋杰这个问题也讲了,他讲的相对高阶一点,我们这里是比较初阶的内容。
在解锁的时候,可以看到它推了两个锁定脚本进去,也就是说,你的锁定脚本如果编出来是5k的话,你解锁的时候需要10k。
因为你的解锁定脚本里面都是代码,一定是比较大的,如果你没有做拆分的话,平白无故的变出来两份是很奇怪的,一个是 Ln,一个是 Ln-1,白白占据了双倍的空间。
那么应该怎么优化呢?

我们注意到,前序交易的锁定脚本,不需要传它的完整内容,可以改成传它的哈希。这样 PreImage 传进来锁定脚本以后,把它以同样方式哈希一下,比较二者是否一致就可以了。比较两个哈希,比直接比较它们的内容要省事很多。
这里有个细节,使用了 hash160,就是生成比特币地址的方式,这样的话合约协作时会更方便一些,这是一个小细节。
通过这种方式,我们保证了解锁时,解锁脚本内,只需要传递一份锁定脚本的副本。

好,到这里为止,刚才分成几个步骤,把感应合约的溯源部分完整过了一遍,实际上,不同合约之间的协作也是类似的原理。
在白皮书的编写的时候,我有一个点处理得有点问题,总是把溯源和协作同时讲解,这样是不对的。后来我意识到这个问题,其实是应该拆成两份文档,一份专门讲溯源,一份专门讲协作,这样大家就不需要同时跟两条线。之后我会改进这个问题,毕竟白皮书才 v0.2 版对吧。晚点的时候我们希望能有一个更好的版本给大家。
答疑
好,接下来我会对一些问题做一些集中的回答。

第一个最常被问到的问题,为什么我们不能把这个签名器放到合约里?
很多人用各种方式问了这个问题,为什么需要额外加一个签名器,而不是把计算过程通过合约本身来实现呢?这样不就消除了对外部机制的依赖了。
简单说一下,如果你要对一个数据做签名,那么你一定是需要这份数据的,对吧?你需要这个数据,就需要把这份数据放到你能访问的地方,对吧?如果你想要在交易(也就是合约)里处理,那你就得把这个数据放到交易里,对吧?你放交易里你就会膨胀,就就绕回到原点了,只要你通过任何方式你把它放进去,那你就会膨胀。
我们签名的目的,就是为了把导致膨胀的因素,从区块链上移下来,弄到链外去。而这种迁移是有技巧的,有多种不同的迁移方式。通过签名器来移,最大的好处就是,能保证签名器本身的行为足够单一固定,它处理的数据也是单一固定的。相对而言,你不用太担心签名器代码写的不好,出bug了或者什么特殊情况,因为它很简单非常简单,就那么几十行。越简单的东西,出 bug 的可能性就越低。
并且,由于签名器没有状态,也不需要你去维护它,你甚至都不需要给他一个很好的服务器,因为他只是执行了非常朴素的一个运算,在实践当中我们是部署在 aws 的 lambda 上面,用腾讯云的话就是云函数,你用个云函数,连存储都不需要,云函数还是免费送的,就可以一直不停的跑签名了。
简单说,你不应该把这些数据弄到链上,因为只要你弄到链上,就会造成它的臃肿膨胀,那么就需要一个额外的链下签名器。

第二个问题,为什么升级 PreImage 就不需要签名了?大家看白皮书里边有一段专门说了这个问题。感应合约有两个实现,一个实现是通过一个外部的签名器,而另一个实现是在 PreImage 的 10 个字段之后,再增加两个字段,一个字段用于溯源,一个字段用于协作。
增加的字段是什么?去对之前交易的数据进行希,然后确保我们可以在解锁脚本里把对应的信息传进去,来验证他们俩是不是有效的。为什么我们在这个节点软件里边做更好,因为节点软件里面有足够的上下文,因为 C++ 里啥都有,你直接在里边算好了,从整个系统的角度来讲,其实是最优解,系统结构也是更简单的。我们认为这是一个合理的天然的操作,但是因为这涉及到对 PreImage 的修改,这个问题争议非常大,从它诞生的第一天争议就非常大。

我们来看看具体有什么争议。有不少关心这个问题的人,他们也许根本都不关心感应合约具体做了些什么,他们就关心这个,反复问,你这个东西是要掀桌子吗,是想要把基本协议给改掉吗?其实不是的,这恰恰是这个提案最重要的地方,而且是最精巧的地方。
在感应合约之前,我们也看到了一些方案,这些方案确实是需要修改协议。而感应合约不同的是,它保证了修改只是针对 PreImage 本身,而 PreImage 我们认为它是 2016 年,也就是后期才被引入比特币的软件实现。它的出现也是有很多历史原因导致的。
我们认为 PreImage 不是比特币原始的基本协议的一部分,只是一个实现软件实现,我们认为升级一下,应该是问题不大的。当然这个事情非常有争议,我们可能出于立场的不同,对这个问题的看法是不一样的。回到刚才这个问题,升级 PreImage,最大的好处就是,我们连额外的签名机制都不需要了,这是对所有人都方便了。
但是在这里我还想补充一点,如果说我们开了这个口子,假设我们在某个几率很低的情况下,真的改了 PreImage,并不意味着就一劳永逸,无需再改了,随着发展总是会涌现出新的需求。
也许就像 Xiaohui 说的,你可能明天又需要什么新功能,是不是又要改 PreImage?小明能改,那小红能不能改?小蓝呢?
这个时候,可能就需要有一个人,或者一个标准委员会这样的组织,来鉴别哪些改动,从比特币发展的角度来讲,是长期有益的。
从实践中,各位也能看到,在比特币发展的十年的历史里面,节点软件引入了各种各样的东西。在那之前好像并没有一个类似以太坊的机制,来使得我们以一种有效的方式来迭代比特币软件。它的成长可以说是一种自然的成长,并不是一种人为规定的发展方向。包括是追溯到最开始的 1MB 的限制,都是以一种自然的状态(被加上去的)。这里是不是应该加一个 1MB 的限制,防止被攻击?好,那就加呗。那就加上去了。
这可能涉及到更深层次的问题了,就是一个软件究竟应该怎样被开发出来才是合理的。
《大教堂与集市》。不知道大家是否看过这本书。它主要讲的是,究竟是通过集市的方式,闹哄哄的开源市场,大家你一砖我一瓦来建设一个集市的方式,来造一个软件,还是通过严谨的规划和系统性的设计,来造出一个浑然一体,金碧辉煌的大教堂,一直都是争论的焦点。
有的人觉得,靠开源的方式,我就能造出大教堂,你看看 Linux 不是典型的例子吗,对吧。
我说下我的看法,首先以我的见识我很难去判断这样一定是不行的,那样一定是行的,但是我想说,大教堂有大教堂的可取之处,而且大教堂造出来的东西,真的有可能是其他方式不一定能造出来的。
集市有集市的优点,集市的方式也能造出来很好的东西,这一点我们都看到了。说回 Linux,据我了解,Linux的社区近年来有什么问题?近年来,年轻人不再喜欢这种方式了。大家原来以为,开源是一个不可逆转的趋势,所有的人早晚都会来开源社区做贡献,会形成蒸蒸日上,日益增长的开发者社区。但是你可以看到,Linux 的核心开发者越来越少,第一越来越少,第二没有年轻人愿意来,全部是老人,全部是像我这样或者比我更大,比我大五六岁甚至十来岁的四五十岁的程序员。这反映了一种趋势,我不知道这个趋势是5年到10年的趋势,还是更长时间的趋势。似乎大家对这样的方式去构造软件,能否最终达到一个理想的结果,是开始有了疑虑的。
这里时间关系我就不展开了。我个人的立场是,如果有可能的话,我会倾向于尽量去开源贡献我的东西,然而对于一个确定性的目标,我们要做长期的规划,用商业的方式去做可能会更适宜。总得来说,这两种方式我都不排斥,在不同的情况下以不同的方式去做好了。这个可能偏题了,跑的有点远,借这个机会跟大家分享一下我的一些想法。

好,第4个问题,你说你这个系统能保证没法伪造对吧,真的没法伪造吗?
我们来试一下就知道了。
假设有一个输出,这个输出我们叫它 Outputfake,就是伪造的输出,里面包含了一笔看起来一模一样的锁定脚本。这个输出来自于交易 TXn’。那么这个伪造的 TXn’ 它在溯源的时候会失败,为什么?因为它溯源需要提供一个合法的 TXn’-1。
也就是说,光伪造你自己不行,你得伪造你的上一笔。这时候你就遇到问题,你可以说,我可以一直伪造上去,对,没问题,如果你一直伪造,最终一定会来到一笔系统外的交易,那个时候仍然绕不开上面这个问题,也就是前一笔和前前一笔之间的相关性的问题。
伪造交易 PreTX,与一个系统之外的 PrePreTX,无法顺利建立相关性。
你可以伪造自己,也可以伪造自己的后继交易,但是你没法伪造自己的前序交易。你没有办法伪造一个已经发生了的事实,一个伪造的交易,一定是来源于一个不合法的交易,对吧?它一定是来源于一个不合法的交易,那才谈得上是伪造,如果你来源于一个真实的交易,就谈不上伪造了。
如果你提供了一个真实的交易,你就不是伪造,你是真的;如果你都提供不了的话,你这个一定是溯源会失败的,你自己就没法被解锁,你的后代当然也是没法被解锁,那就说明什么?说明你自己和你的后代不能够有效的通过溯源来关联到一起。
你只能伪造未来,不能伪造过去,你之前的发生的事实,是已经既定的事实,想伪造就一定是来源于一个系统之外的tx,这样就没办法建立这种相关性,于是溯源的时候就会失败,这是整个系统的核心逻辑。

好,还有一个经常被问到的问题,就是签名器作恶有什么办法,传什么参数都给你返回 True,或者说是被黑了,或者是服务器过期了,签名器不可用,等等,怎么办?
因为今天早上第一节课是一个基础理论性质的课,我只谈最基本的东西。扩展的高级话题,陈诚和蒋杰会给大家分享。最基本的方案,就是在你的合约里边包含多个公钥,比如说包含20个,然后只要其中的10个认为有效,我们就认为是合理的。
一下子攻击 10 个签名器的概率是比较低的,那么就可以保证这个系统,至少在签名器这一层是健壮的。更高级一点的办法就是蒋杰昨天说到的版本号机制,可以淘汰老的签名器,增加新的甚至还有更高级的用法。我们开发群里边比较活跃,旺仔在公钥授权这块也提了一些很好的想法。

剩下的两页内容实际上是第一天工具概览时候的内容,为了完整性,我也把它包含进来了,可以作为一个回顾。
感应合约有几个特性,跟其他的方案相比,它是没有外部状态的,oracle 不需要认证,然后它不需要额外的 op-return。它的数据段是包含在合约里的,你可以对它进行一些操作和验证,然后它是完全由矿工来验证的,而且它对比特币的其他的机制是友好的,我们可以说它 “bitcoinic”,比如说 metanet 可以跟他一起很好的工作。今天下午会跟大家分享一下这一块的案例。而且它是跟 bitcoin 一样是支持 SPV 的,既不比比特币更多,也不比比特币更少。
你的模型,可以体现出跟比特币本身类似的特性,是非常有趣,也非常有用的。它带来的潜在好处,可能大于我们原先的认识。
比如说像昨天群里有同学问,冻结(Freeze)怎么样,能实现吗?
当时我跟蒋杰讨论,第一反应就是,这功能不难实现。蒋杰跟我说,就签名器里边弄一下就好了。实际上,如果什么(新加的功能)都在签名器里弄,长期看又会遇到 Xiaohui 说的那个问题,你今天加这个,明天加那个,到底什么能加,什么不能加,到时候需求虽然满足了,加来加去,你那个东西又会很大,又会越来越臃肿,越来越庞大,是一个庞大的链外机制,这样真的好吗。那么实际上,我们可能真不一定需要做那么多,我们只要让它保证它像比特币一样就可以了,比特币能封,比特币的 utxo 能封,我就能封;比特币如果不能封,我也不能封,就好了。我们目前看没必要把精力花在这个上面。
当然了,你可以说,我就是要实现一个合约,它就是要能封,你怎么办?你可以通过特定的机制,一些高级的用法,等会儿陈诚和蒋杰会分享。这种分享是会持续进行下去的,我们之后会做很多相关的开发工作,大家如果真的对各种新的特性感兴趣,也可以加我们的开发群,在里面跟我们一起讨论,你可以看到很多人一些很有创意的想法,实现各种各样好玩的东西,包括一些通过抵押惩罚来保证额外的安全性,这些都是很有意思的话题。

好,还是跟第一天一样,我简单提一下它的两个缺点,第一个是引入了一个额外的签名器,第二个是因为你的绝大部分核心业务逻辑都在合约里,导致你的合约的尺寸会比那些 “把这些关键逻辑放到外头,合约只是作为一个承载物” 的方案,合约尺寸要大一些,会导致这个问题。
礼拜一的时候我举了个例子,后来有人来问我,我稍微具体的说一下,我们的结算有一笔结算是100个输出,每一个输出是8k就导致有800多k,我举这个例子不是说交易有多大,而是说我们做了优化,使得它的单个锁定脚本很小,只有8k。是这个意思。朋友说你这个是不是要说你弄能弄到多大,我说能弄到多大,你想弄多大就弄多大,这取决于上限(目前 TAAL 是 100KB)。
我们确实是因为逻辑在合约里导致合约尺寸比人家大一些,但这些是可以通过一些方式去消解和简化的,等会就可以听到一些方案是可以缓解这个问题,甚至说能够做得比其他方案尺寸更小。我们也相信 scrypt 会在脚本尺寸这一块做出很多努力来优化,这里面的优化空间优化余地是非常大的。

好,最后我们说一下 BCP。我们为什么要在比特币上去做一些模板这样的东西。其实是为了方便大家开发,提供一个默认的东西,这样每个人不用自己再去重新实现一套自己的东西。你可以不用,或者说你可以 copy 去随便改,改成自己的都没有没问题,只是给你一个很好的出发点。
那么我们定义的这些 BCP 反映的是协议的自动化,正如周一时所说,把协议的自动化拆分成交易步骤,并且使得他们可以整体上被直接使用,能够节省大量的时间。
从外界的观感上来讲,如果你封装的足够好,外界可以不用理解什么细节,我们讨论过一些有趣的东西,怎么把它给隐藏起来,让外界不用关心这个东西,用的时候不用太关心底下成熟的基础细节。

好,这就是我今天的分享,谢谢大家。有问题的话可以问。
现场问题解答
签名器的角色问题
问:我有一个问题,就是说如果说交易量非常大的时候,这个就是提供签名期的这一方,他的动力是他怎么有动力去运行签名器,就说你跟因为每个token都会有一个发行方吗,然后你运行签名器的这一方和 token发行方会是之间会是什么样的角色,什么样的关系?
这个问题可以用两点来回答。
我们有一个直觉就是签名器好像是个第三方,但是他可以不是第三方。它可以是一个函数,所有的工具都可以集成这个函数,你什么地方都可以运行。当他足够成熟的时候,你可以预见的是绝大部分支持 Sensible 的基础设施都有可能内置,可以交叉验证,这是第一点。
第二点,签名器是可以有一个独立的输出给他送钱的,你每签一个名,都可以给他钱。可以通过这种方式来激励不同的人运行不同的签名器,并且你可以通过来看这个签名器曾经签过多少名,来了解他的历史访问情况。他会为自己累积声誉,你就会在你写合约的时候,选择那几个声誉很好的,没出过问题的签名器,把他们的公钥给记下来。
为什么要执着于把 token 做到层一去?
问:
呃我还有一个问题就是说,因为在包括之前的 btc 上面也有基于 omni 的 usdt 对吧?这样的合约,包括在 bch 市场也曾经有过,然后 bsv 里面现在更多各种各样的 token 的方案,互相之间肯定是有差异。
我记得你上次讲的时候,有一个表从纯一层到二层之间过渡的这样的一个,但是我觉得就是说 usdt 去发这个上面已经有很大的交易量,然后用起来也没有出现过什么问题,本身发行方他为自己负责,就是我去保证说我的所有这些 token 的总量,然后转移的这个合法性好像也没有什么问题。
我们为什么就比较执着于说要求我把它做到一层去,用合约的方式来保证?
还是说,是不是可以用另外一种方式,我做到二层,然后用这种比如说我发行方的信誉,或者说法律的手段去保证。
这中间有什么考虑?
答:
应该这么说。通过二层本身是没有问题的,毕竟人家跑了那么多了对吧。然后,是这样一个问题,我们究竟是选择用技术的方式去处理,还是选择通过法律来保证这个主体是合法的有效的,是不作恶的。这是一个非常有争议的问题。
按照正统的政治正确的方式来说,我们要靠法律,对吧?毕竟 code is code, law is law.
但是从现实的角度来讲,你通过技术来保证,可能会成本更低。通过技术来保证成本更低了以后,也不排除用法律对吧?你用技术实现了成本更低的方案了以后,法律仍然是可以介入的,这两者没有直接的冲突。
所以还是回答刚才那个问题,就是用一层的方案来实现,也许看起来好像是在试图说 code is law 的意思是吧?“在一层解决” 看起来是试图在用技术来解决一个(从二层的角度看)归法律管的问题。但是,我可以提供一个不同的解释,你通过技术来实现了低成本,然后法律仍然是可以保证的,你并没有牺牲掉什么对吧,但是你获得了额外的好处。
(全文完)