
tl;dr (“Too long; didn’t read.”)
信息过载是我们每天都要面对的问题。有趣的是,随着信息鉴别,过滤,处理能力的提高,我们往往不自觉地会延展自己的信息渠道(新 app、新 feed 和新的公众号,等等),接着让自己陷入更大的信息漩涡——明明是效率提高了,吞吐量增大了,为什么好像每个人都更加不堪重负了?
It’s not information overload. It’s filter failure.
- Clay Shirky, excerpted from Information overload (Wikipedia)
在即将过去的 2016 年,我形成了一些小习惯,帮助自己更好地应对信息过载的难题。整理一下,分享给有同样困扰的同学。本文中,我会列出一些自己觉得好用的小技巧,然后是作为容器的信息库的分拣标准,最后谈一下我是如何用最低的时间成本去维护这套体系的。
tl;dr - (chiefly Internet) “Too long; didn’t read.” Used to indicate that one did not read a (long) text, or to introduce a short summary of an overly long text.
- Excerpted from tl;dr (Wikipedia)
小技巧列表 (5个)
技巧1:10 秒处置

当你处于碎片阅读的状态(随便读读)时,即使遇到再有价值的文章(最新的例子是 Milo 老师的游戏程序员的学习之路——真不想放这个链接,因为精彩到很多人点进去估计就忘了回来读本文了 Orz..),再有趣的故事,再不能错过的视频,也要能克制一直读完的冲动——除非它短到 30 秒以内就能完成。取而代之的是,为它建一个后续的条目,在合适的时候再决定是不是真的要读下去。
这样做的最大好处在于——能让你在最短时间内意识到,很多不知不觉读完的材料其实是不值得读的。要学会随时用你的 inner voice 对自己喊:“Cut!!”。况且,**“新建一个条目”**这个额外的动作本身是有3秒钟时间成本的,这本身就是一道坎,如果连这额外3秒钟我们都要琢磨一下,那这材料很有可能不值得继续读下去。

既然你是在碎片阅读,那就应该真正做到以碎片化的方式去阅读。如果总是由着兴趣敞开了读,那么你的阅读过程最有可能变成这样:
- 短–短–**长——————**短–**长————————–**短–
而事后看,中间的长文未必总是值得读的,那么时间就在不知不觉中浪费了。
像上面那样的短长交错的模式,其实还算是好的,如果你真的遇到一个精彩的长文,更有可能变成这样:
- 短–短–长——————————————————(被打断/未读完)
这个偶遇的长文将占据你余下的所有碎片时间,而且你几乎肯定不会读完——通常是在外部环境变化时(如车来了)才发现自己兴致勃勃地读到一半——匆匆地收藏一下,就关上手机结束了这次阅读。这样,你实际上花了不少额外时间(假设是正常读完全文所需的一半时间)来做了一个收藏的决定。
即使日后仍有幸记得回来打开收藏把它读完,还是要花时间去补回脑海中的上下文,这样你读一篇文章的总时间开销将是你正常阅读的 1.5 倍;而倘若你不再记得回来续读,或者回来时又觉得“这篇文章似乎不如刚读到时那么有趣了”,决定不读了,那前面那一半你就白读了。
所以你看,这么做是很低效的——不管你日后读还是不读,当下的时间都被浪费掉了。
在碎片阅读时,试着让自己习惯于喊 “Cut”——即使你遇到的材料再精彩,也尽量保持克制——能让你的阅读过程变成下面这样:
- 短–短–短–短–短–短–短–短–短–短–短–短–短–短–短–短–
当这样的节奏形成习惯以后,能让你更有效地利用碎片时间——任何时间点上结束都不会有“没读完”的心理负担,这才是真正的“碎片化阅读”。
“10 秒处置” 发生于接触信息的第一时间点,是我个人在信息处置方面的最佳实践。如能善加运用,“10 秒处置”这个简单的原则就能成为个人信息边界的第一道防线,可以帮你以最小的时间代价抵御最大量的信息攻击。所以作为性价比最高的技巧,这条原则被我排在第一个讲,希望能对阅读此文的你有所助益。
如果你的时间非常宝贵,读到这里就打算结束阅读本文,那么可以说你已经获得了本文最有价值的一条小技巧,可以安心地关闭页面离开了。
技巧2:把 “read it later” 改为 “read it at 20:45”
当你在 10 秒处置时决定认可一篇文章的价值,打算把它收藏起来以便日后认真阅读时,是直接点一下“收藏”就完事了吗?
以前我就是这么做的。但后来我发现,所有那些收藏起来以便日后再读的文章,十有八九都石沉大海了。新的信息前仆后继地潮水般扑面涌来,永无休止地反复堆砌在老旧信息之上。层层碾压之下,老的收藏几乎无法获得被再次认真阅读的机会。

正如@顾煜老师说到的那样,Read it later 变成了 Read it never。
意识到这一点之后,我在 2016 年养成的第二个习惯是——任何时候触发“收藏”或类似的动作(如加入阅读列表),都明确地为这个收藏打一个目标阅读时间的标签("read-time" tag),这个标签可以是:
- 明确的目标时间点,如:20:45 today
- 明确的目标时间段,如:this week / this month / this year
- 不明确(不明确本身也是一种明确),如:someday / after xxx is done / pending
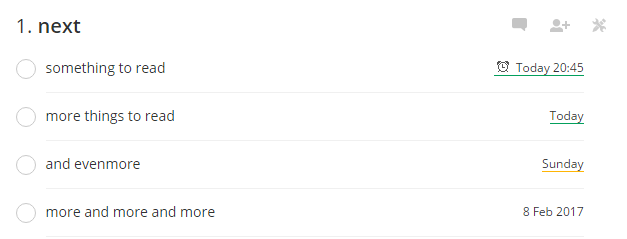
这样做的好处是——你随时可以通过标签查找,知道自己接下来的指定时间段里阅读任务重不重,然后重估和调整自己的阅读量。当你真的有整块的时间静心阅读时,可以立即开始阅读这个时间点上的存货,而不是在收藏夹里东翻翻西看看,把时间和心智浪费在反复挑选适合阅读的材料上。
我常用的 Pocket 阅读列表,微信收藏和印象笔记·剪藏,都支持“为新增条目指定任意数目个标签”。当然标签还有许多其它的用途(比如打上阅读这段材料大约会占据的时间,如“10min”, “1h” 等等),这里跟本条目无关,就不多说了。
更优秀的阅读列表(比如高级版 Todoist)允许你定义一条提醒,到时间了提醒你读,并直接把文章链接或内容推送到通知栏。如果主动取消或没有及时阅读,它能自动把过期的条目聚合到一起 (overdue),让你知道自己的估算有误,下次就可以估得更准确。
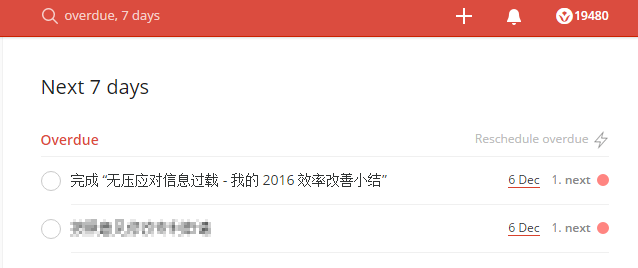
呃,好吧,截完图才发现,此文本来计划两天前(6 Dec)就完成的——一篇谈效率的文章本身延期了——真是给自己跪了——囧rz…

“定义明确的时间点”这个动作同样有助于你把那些可读可不读的材料拒之门外,比如 “read it someday” 通常意味着“虽然觉得有点用,可还是先一边待着去吧”,将其物理隔离于你的日常待选列表之外——直到因为某个新情况的发生你提高了它的优先级——或(更多情况下)一直得不到宠幸,晚些时候被清理掉。
技巧3:数目限制以免超量
刚开始打标签的时候很容易滥用 today。我自己最开始经常的情况是,一天下来攒了十几二十条标记 today,一晚上连一半都读不完,完全超出了自己的可行阅读量。只能全部 push to tomorrow,结果日复一日地滚雪球,标签就白打了。
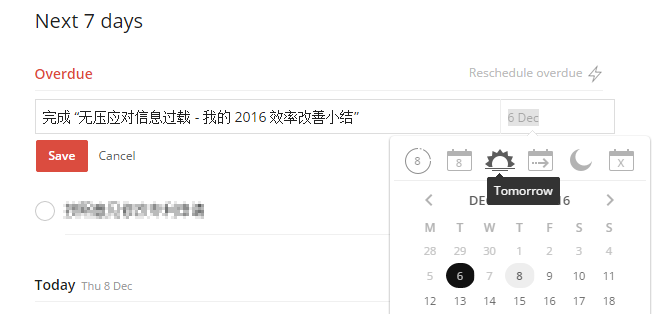
看,过期事项只要轻轻点一下(有段时间是我点得最多最勤的按钮了)就可以推给明天了,明日复明日,真是邪恶的功能啊。
|
|
这当中最重要的是对自己的阅读强度,阅读材料量和用于阅读的时间量有正确的预估。跟健身一样,一开始就做准确的预估是比较难的,不妨把数量定得低一些——先定一个小目标——一天一篇深度阅读,有把握之后再逐渐增加。坚持四周习惯养成之后就不用刻意地算着排了,你的节奏感和潜意识在 “10 秒处置” 时往往就能自动帮你作出条件反射式的决定和安排。
我目前通常是3-5篇,每篇平均十分钟左右,也就是一天下来精读的阅读量在半小时在一个小时之间。这样虽然远远比不上那些速读大神,但好处是没啥负担就可以完成,不至于排得太满增加无谓的压力。
另外,排的时候我也会注意内容的分布,通常不会在某一天全部是同类,而是从浅到深各类的都会有一些,这样比较不会觉得疲劳。如果当天的状态很好可能会多排深入的材料,反之会更娱乐化和消遣一些。毕竟没必要把自己当成机器,不必强求定量的输入。
技巧4:即刻奖励和迷你成就系统

给自己的鼓励和奖励并不像看起来那么幼稚。
在百万年的进化之中,“行动-成功-收获-喜悦-再行动”和“行动-失败-放弃-沮丧-不再行动” 这样的即时反馈机制已经深深地镌刻在我们的基因之中——对于资源极度匮乏的漫长的原始人类时期,每个行动点上的即刻奖励往往就是生存本身,无法形成正向反馈循环的个体在漫长的进化过程中都会被淘汰。
如果你和我一样喜欢玩游戏的话一定明白我在说什么,精心设计的游戏总是会制造持续的积极反馈来吸引你的注意力一直玩下去,小到超级玛丽里面不断吃到金币,大到魔兽世界的多人副本体验。而相对的,缺乏积极反馈的游戏过程很容易就被中断掉。

即使通过培养超强的自律,信仰,使命感等自我驱动机制,使你脱离了任何即刻的反馈也可以持续地完成既定目标,即时奖励仍然有巨大的积极意义。它会向你自己释放认可和满足的信号,具体到接收信息这个任务里,完成既定的阅读目标后的奖励,让你可以随时提醒自己阶段性目标的实现,解除当下的心智负担。
定义各种迷你的主题成就,可以赋予零碎的信息接收以完整的意义,在日后回顾时,也能很容易地找到来时的路。那些历史上纵横寰宇的伟人,自有无数仰慕者为其树碑立传——而对吾辈凡人而言,这些由自己定义的小小成就,即是自身每一段成长的点滴见证。

技巧5:batch reading (批量阅读)分摊心智展开的开销
在不太熟悉的领域,对于有深度的文章,我们往往需要起步阶段的思维铺垫和心智展开的过程。如果阅读时一味图快,往往只能懂个大概,无法真正地消化吸收,为己所用。在这种时候,把针对同一主题的不同角度的文章放到一起阅读,往往在互相印证,加深理解的同时,避免了多次展开的时间和心智开销。材料越多样,细节越丰富,越有助于我们的潜意识去自动地梳理和提炼。
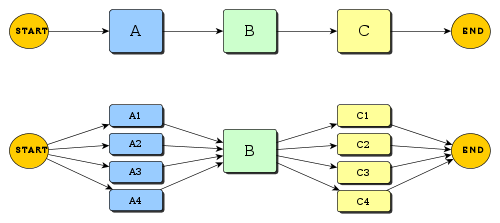
从上图可以看出,针对同一主题的批量阅读往往比单一的阅读更有效率,对该主题获得的认识更深入。
有时,我们会遇到自己很感兴趣,但是一看就知道当下还读不懂的文章。这就是很好的日后 batch 的对象。我一般会打个 pending for batch 的标签。攒了三五篇同一主题却深浅程度不一的文章之后,一鼓作气读下来,收获会很大——这可比“零打碎敲,读了不少却始终保持在一知半解的程度”要来得有效率多了。
我的信息库
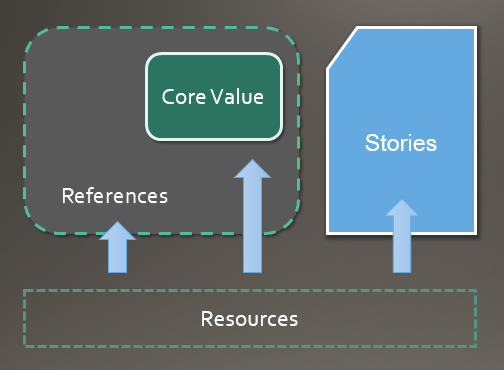
日常的 GTD 加上以上的筛选技巧就是我的日常信息流水线,而流水线的产出就是我的信息储存体系,包含下面四个部分:
- core value - 这部分是我能提供的核心价值所在,包括了我最擅长的技能及相关的领域经验和知识积累,信息质量和密度最高,深度优先,主要保存为有完全修订历史的 markdown 文档。
- references - 这部分是对我而言是非核心的外部参考和引用,会对吸收的信息做一定的提炼,广度优先,主要保存于 Evernote 类信息采集软件。
- stories - 各类演讲或公开课,各种故事,奇闻,都市传说,行业会议,各类政经文史哲材料,等等,以保证原材料的完整性为主要考虑,主要档案格式为 PDF。
- resources - 各类资源工具文档的聚合,外部服务,等等,散见于书签,收藏夹及各类 app 里。
惰性整理法则:维护——用最低的时间成本
惰性整理法则:如果专门花时间整理,容易陷入为了整理而整理的泥潭,时间花很多但性价比低,当时感觉整理得很好,但大多数材料是有多维视角的,整理时为了效率往往只考虑了单一的角度。
更好的做法就是打上时间戳,任其自然按照日期排列,不做任何整理。当新的材料出现的时候,只有我们很明显地觉察到几份材料的相关度足够强时,再把它们放在一起,让这些材料自发的聚合。这样不仅时间开销极低,也能辅助着把头脑当中的零碎知识点聚点成线,聚线成面,聚沙成塔。更重要的是,我们清楚地知道,每一次清理都能有效提高有序程度,以最小的代价降低系统的熵。
适度的混乱加上惰性整理可以让我们做到 clean-on-demand,从反复整理的大块时间浪费的泥潭当中解脱出来。正如增量式垃圾回收每次只处理一小部分那样,惰性整理本质上是一种增量式的渐进整理。
小结
对于看重成长的个体来说,个人效率是一个永恒的话题。摆脱松鼠症,绝非一日之功;消除长期积累的内心的焦虑和不安,更不是掌握几个小技巧就能做到,需要的更多的是根植内心的耐心和勇气。记此小文,聊以自勉。
(全文完)